Code
library(readxl)
df <- read_excel("_data/LungCapData.xls")First, let’s read in the data from the Excel file:
library(readxl)
df <- read_excel("_data/LungCapData.xls")The distribution of LungCap looks as follows:
hist(df$LungCap,freq = FALSE)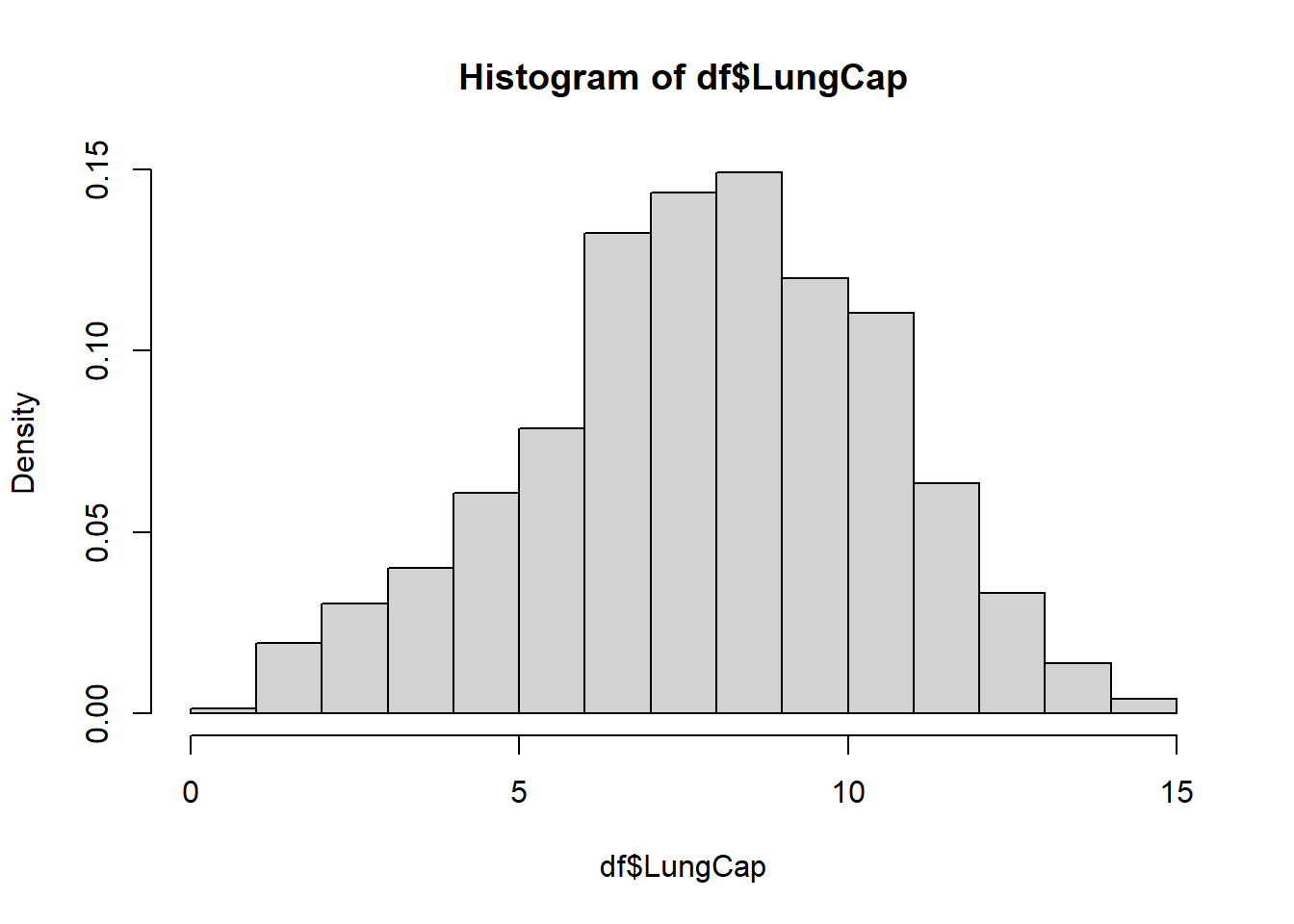
The histogram suggests that the distribution is close to a normal distribution. Most of the observations are close to the mean. Very few observations are close to the margins (0 and 15).
Comparison of the Genders for both Men and Women using a Boxplot.
boxplot(df$LungCap ~ df$Gender)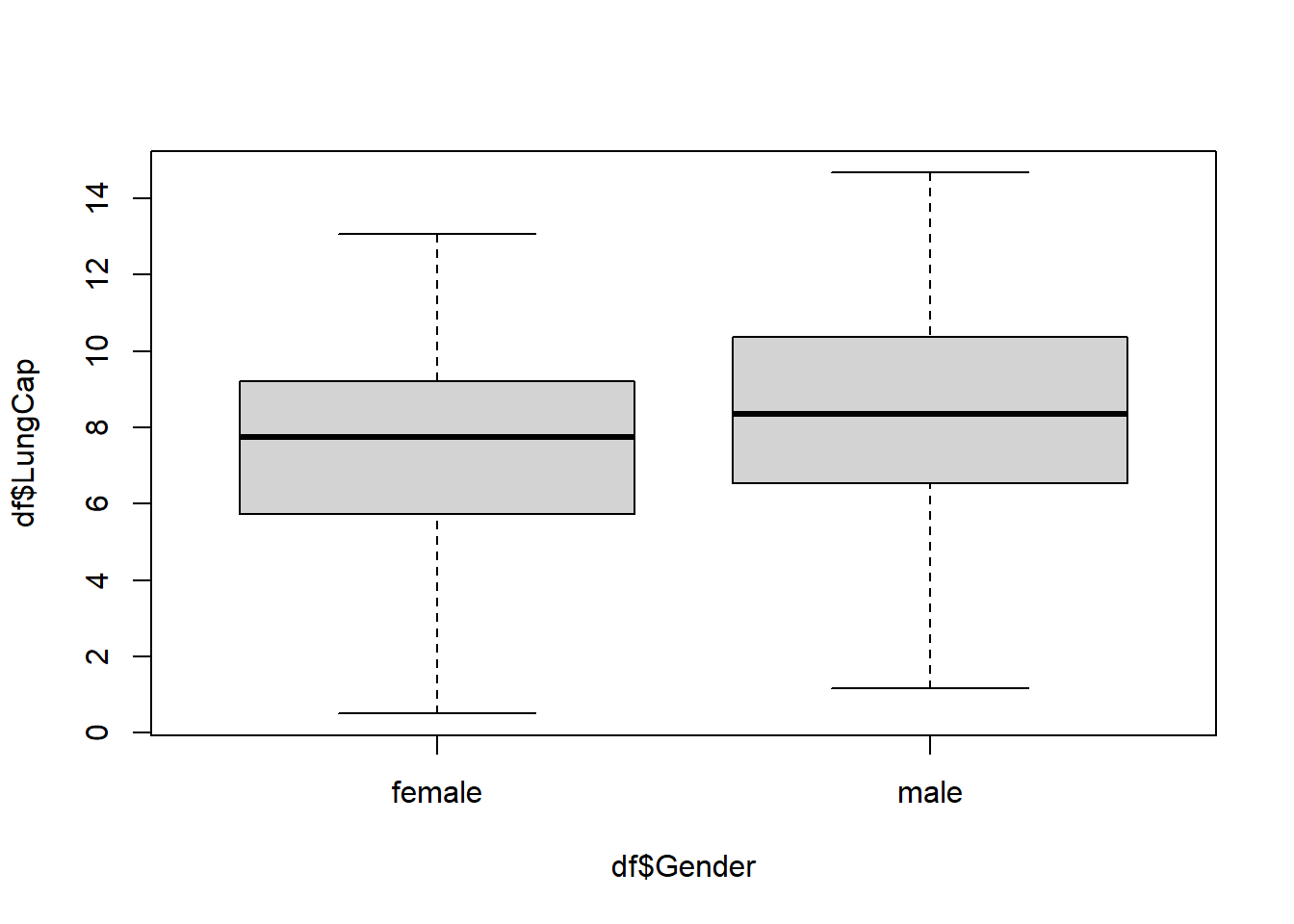
Here is the capacity of Smokers vs Non-Smokers
boxplot(df$LungCap~df$Smoke,
ylab = "Capacity",
main = "Lung Capacity of Smokers Vs Non-Smokers",
las = 1)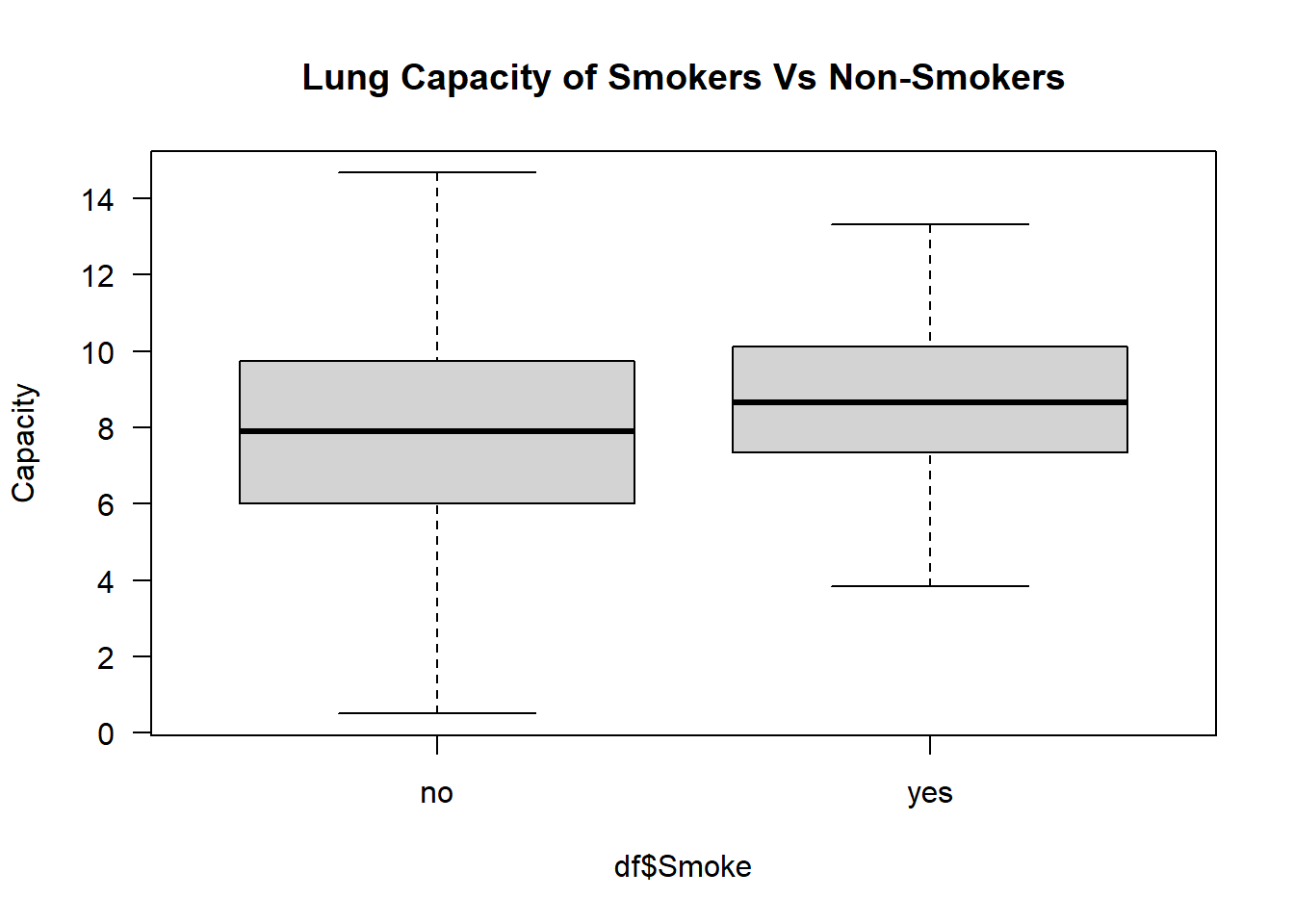
Let’s break it down even further, this is the Lung Capacity by Age Group
df$Agegroups<-cut(df$Age,breaks=c(-Inf, 13, 15, 17, 20), labels=c("0-13 years", "14-15 years", "16-17 years", "18+ years"))Below is the overall Lung Capacity of Age Groups without including Smokers.
library(ggplot2)
ggplot(df, aes(x = LungCap, y = Agegroups, fill = Gender)) +
geom_bar(stat = "identity") +
coord_flip() +
theme_classic()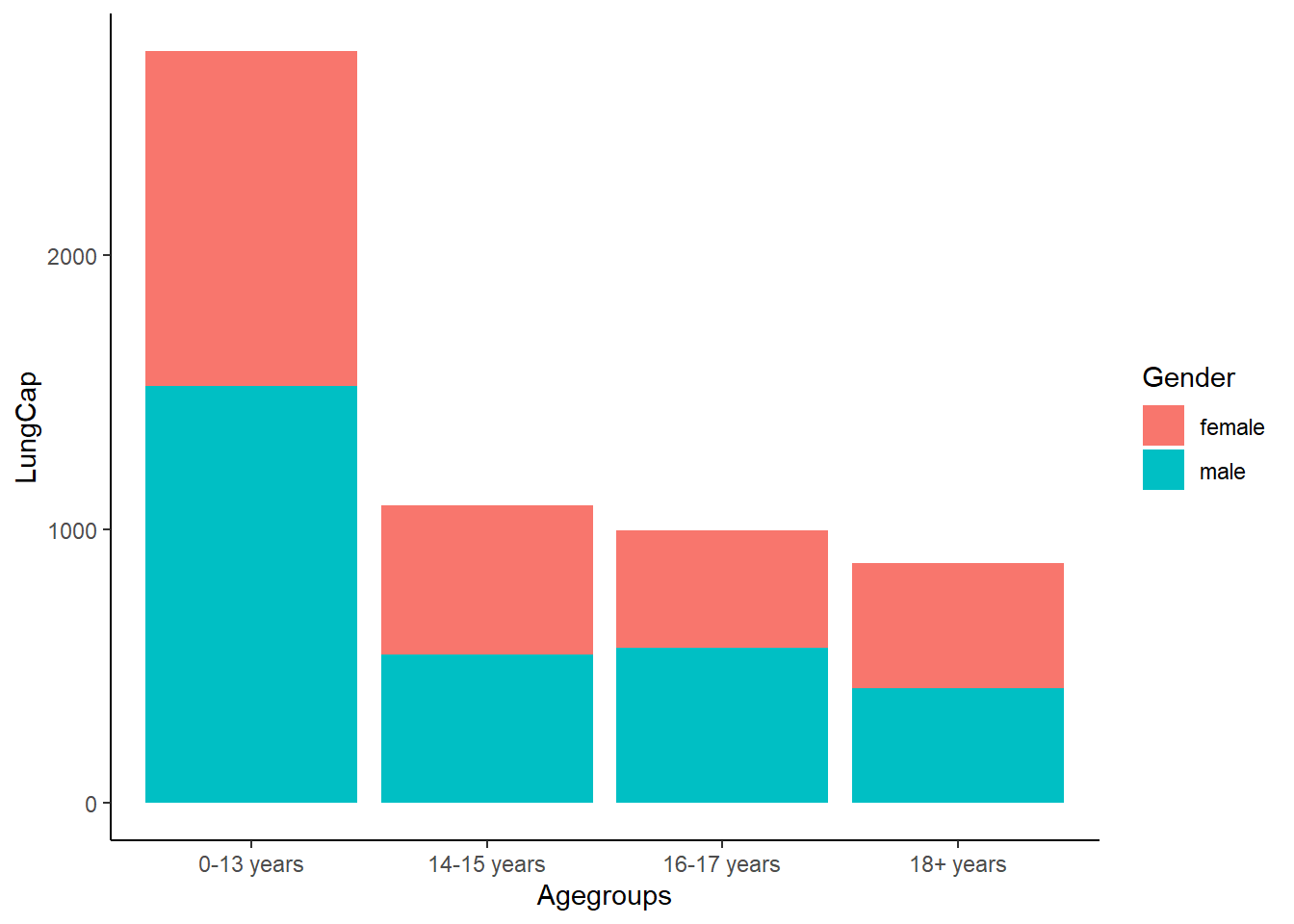
#e
Here is a comparision of AgeGroup Lung Capacity in comparison with Smoker vs Non-Smoker.
ggplot(df, aes(x = LungCap, y = Agegroups, fill = Smoke)) +
geom_bar(stat = "identity") +
coord_flip() +
theme_classic()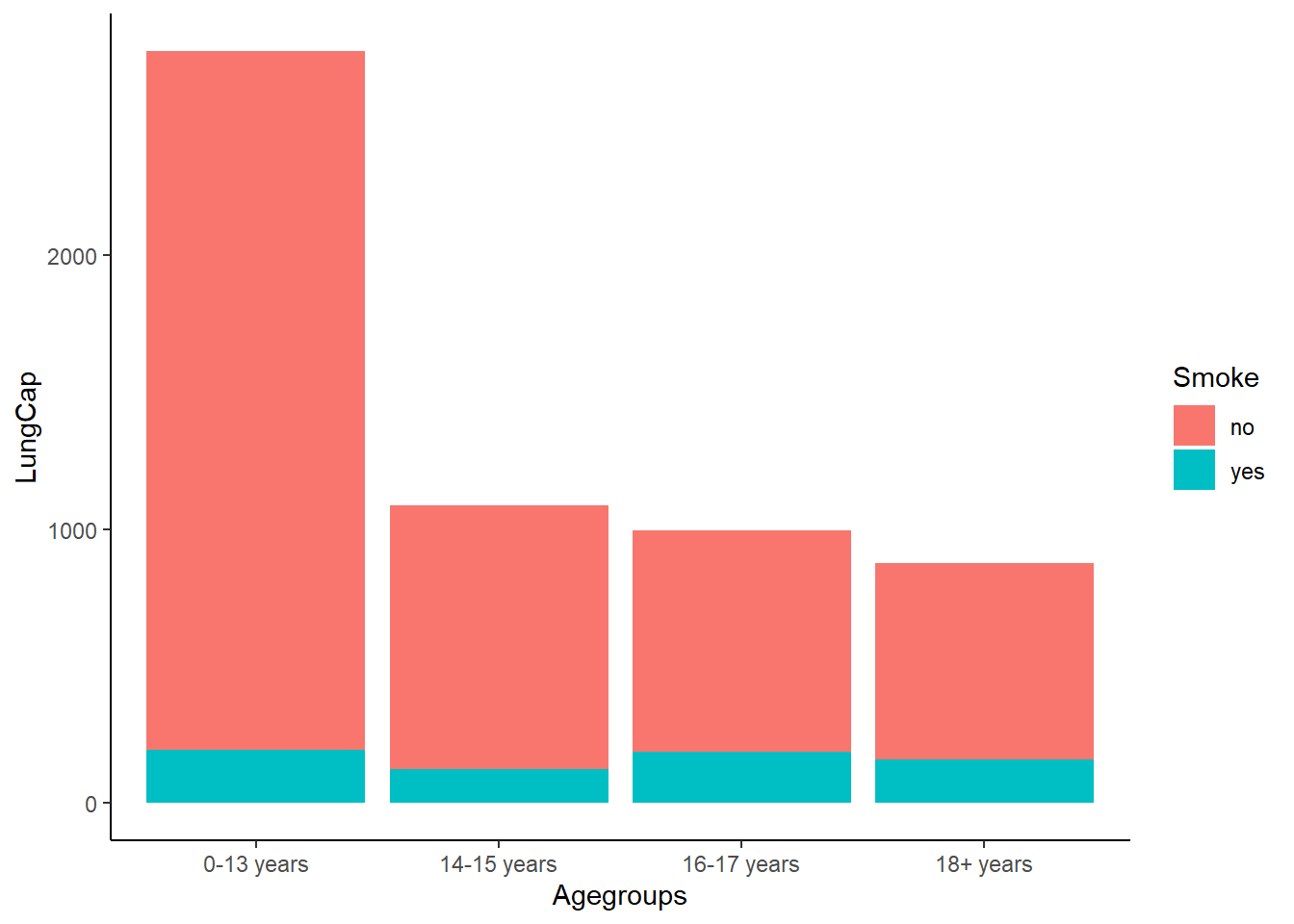
Based on the comparison of lung capacities between Smoker and Non-Smoker the results are pretty similar.
cov(df$LungCap, df$Age)[1] 8.738289cor(df$LungCap, df$Age)[1] 0.8196749Question 2
X <- c(0:4)
Frequency <- c(128, 434, 160, 64, 24)
df <- data.frame(X, Frequency)
df X Frequency
1 0 128
2 1 434
3 2 160
4 3 64
5 4 24As shown below, the most common Prior Convictions is 1.
df X Frequency
1 0 128
2 1 434
3 2 160
4 3 64
5 4 24Dividing by the total among 810 we can determine the probability for each. 810 is the Sum of the Frequency which I checked manually.
df2 <- mutate(df, Probability = Frequency/sum(Frequency))Error in mutate(df, Probability = Frequency/sum(Frequency)): could not find function "mutate"df2Error in eval(expr, envir, enclos): object 'df2' not foundb2 <- df2 %>%
filter(X < 2)Error in df2 %>% filter(X < 2): could not find function "%>%"sum(b2$Probability)Error in eval(expr, envir, enclos): object 'b2' not foundc2 <- df2 %>%
filter(X <= 2)Error in df2 %>% filter(X <= 2): could not find function "%>%"sum(c2$Probability)Error in eval(expr, envir, enclos): object 'c2' not foundFilter for Probability of greater than 2 convictions.
d2 <- df2 %>%
filter(X > 2)Error in df2 %>% filter(X > 2): could not find function "%>%"sum(d2$Probability)Error in eval(expr, envir, enclos): object 'd2' not foundWhat is the expected value of the number of prior convictions?
e <- weighted.mean(df2$X, df2$Probability)Error in weighted.mean(df2$X, df2$Probability): object 'df2' not foundeError in eval(expr, envir, enclos): object 'e' not foundVariance and Standard Deviation for Question.
var(df$X)[1] 2.5sd(df$X)[1] 1.581139